This is the second blog post of a new series entitled “Build it with the Coveo Cloud Platform”. The series will present innovative use cases for the Coveo Platform, always including full code samples. Read the previous post Building a resource locator.
Use case
- Build a demo on top of Coveo for Elasticsearch to show what you can do with the platform.
- Use public content that everybody is familiar with.
- Build it in 2-4 weeks time.
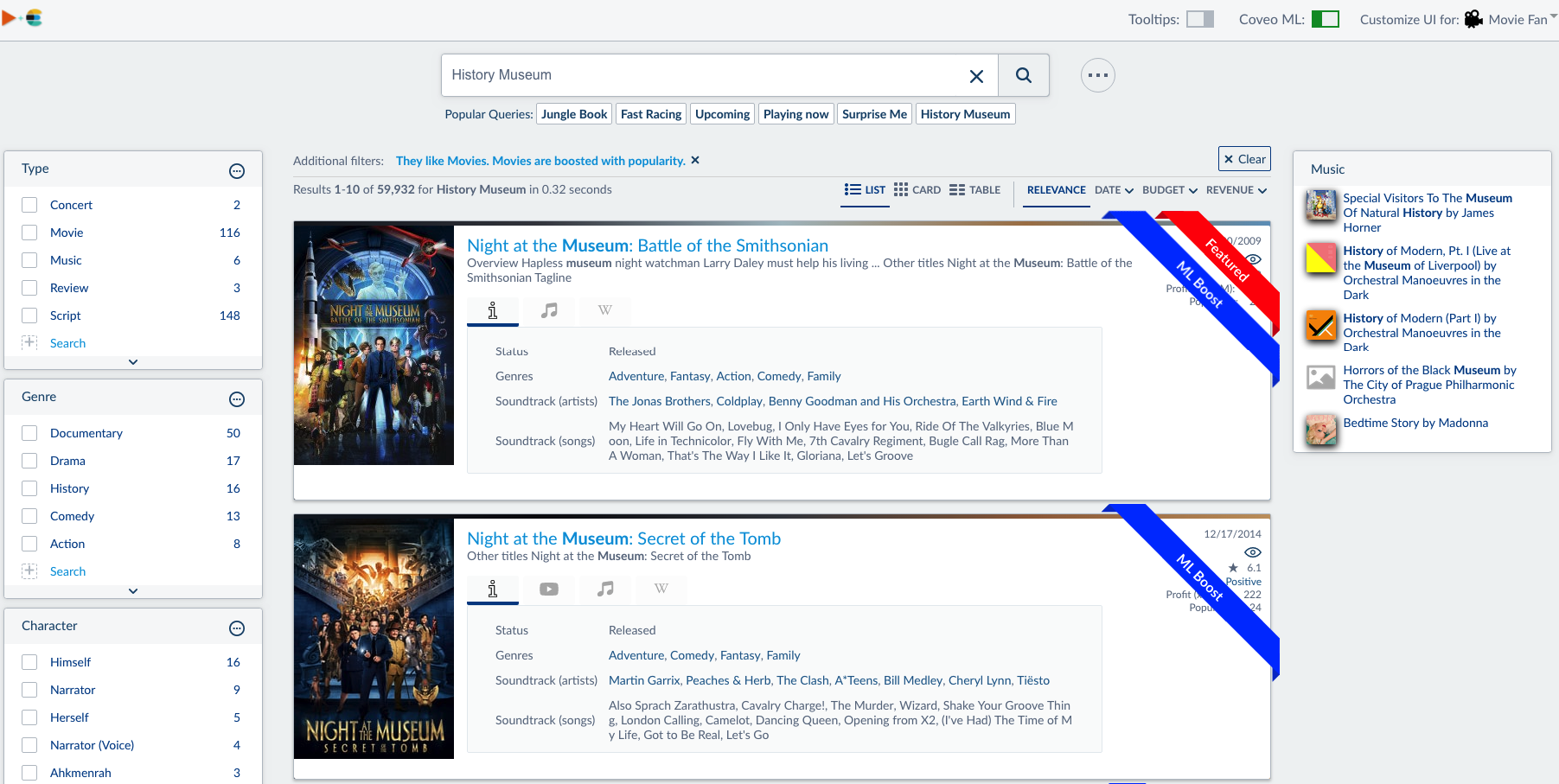
This post is the first post on the Elastic Demo, where we build the index needed for the demo. The next part will cover how to build the UI.
Requirements for the demo
We wanted to have content which is publicly available. We all liked the idea of building a demo based on movies. Based on that, we constructed an index with everything related to movie content. The demo showcased ‘the art of the possible’, so that customers and partners could see what and how they can leverage the Coveo Platform. We also wanted it to include a number of connectors, extension scripts, and UI customizations.
What we wanted to show
Before we even start indexing, we first needed to think about the UI.
We wanted to have a Movie search, with a very rich interface. But besides Movies, it would also be interesting to leverage the Soundtrack data which is available for most of the Movies. Using the Soundtrack data we know the artists and the tracks played in each movie. Going one step further, we also wanted to find those soundtracks, including the albums of each artist. Our ultimate goal was to show the concerts where those artists are performing! From finding a movie, to a great new music album and finally visiting a concert!
To support the features above, we needed the following content inside our index:
- Movie content
- Music/track content
- Additional content, like scripts library, wikipedia content
- Concerts content
Now we only needed to find that content to index it.
What we indexed
After investigating where the content was available (and also public available), we found a number of content repositories. The bad news was that most of them had throttling defined so we really needed to have some scripts which would ‘slowly’ download all the content from the respective API’s. Below is the list of the content we indexed and which connector was used.
| Content Type | Connector | Content |
|---|---|---|
| Books | Web | Movie scripts (web and PDF’s) |
| Concerts | Push | Concert information coming from https://api.songkick.com |
| Movies | Push | Movie information coming from https://www.imdb.com |
| Music | Push | Music tracks from https://www.lastfm.com |
| Wikipedia | Push | enwiki from wikipedia |
| Youtube | Youtube | Youtube movietrailers and Youtube Movies |
| None | Movie tickets search (federated), Special: the current country/region is fetched from ipinfo.io. Using that a search is performed against Google to find the nearby theatres where the movie is playing |
Since the Movie source is the most complicated one, we will deep dive into that later on. The other connectors like Books and Youtube are out of the box connectors.
Deep dive into indexing the Movies.
Step 1: Crawling.
The Movie database (TheMovieDb) has a very rich REST api where we could get all the information we wanted for a movie. We could get the general information, like budget and revenue, but also the featured actors, crew and even reviews.
We got the following JSON from the Movie Database:
{
"alternative_titles": {
"titles": [
{
"iso_3166_1": "FR",
"title": "The passenger france"
}
]
},
"poster_path": "/rDeGK6FIUfVcXmuBdEORPAGPMNg.jpg",
"production_countries": [
{
"iso_3166_1": "US",
"name": "United States of America"
}
],
"revenue": 31642534,
"overview": "A businessman on his daily commute home gets unwittingly caught up in a criminal conspiracy that threatens not only his life but the lives of those around him.",
"allreviews": "",
"video": false,
"keywords": {
"keywords": []
},
"id": 399035,
"genres": [
{
"id": 28,
"name": "Action"
}
],
"title": "The Commuter",
"tagline": "Lives are on the line",
"vote_count": 145,
"homepage": "https://thecommuter.movie/",
"belongs_to_collection": null,
"original_language": "en",
"status": "Released",
"relatedartist": "Blue Mink",
"spoken_languages": [
{
"iso_639_1": "en",
"name": "English"
}
],
"relatedsongs": "Melting Pot;In The Mirror;Un-Named;Ride Of The Valkyries",
"imdb_id": "tt1590193",
"credits": {
"cast": [
{
"name": "Liam Neeson",
"gender": 2,
"character": "Michael MacCauley",
"order": 0,
"credit_id": "57445c4e925141586c0022a1",
"cast_id": 0,
"profile_path": "/9mdAohLsDu36WaXV2N3SQ388bvz.jpg",
"id": 3896
},
{
"name": "Stuart Whelan",
"gender": 2,
"character": "Police Detective (uncredited)",
"order": 56,
"credit_id": "5a53ef660e0a2607d40019b9",
"cast_id": 110,
"profile_path": null,
"id": 1840384
}
],
"crew": [
{
"name": "Jaume Collet-Serra",
"gender": 2,
"department": "Directing",
"job": "Director",
"credit_id": "57445c5992514155be00120b",
"profile_path": "/z7jv5RF9RVZnv32QuMn8YxFgdIg.jpg",
"id": 59521
},
{
"name": "Philip de Blasi",
"gender": 0,
"department": "Writing",
"job": "Writer",
"credit_id": "57445c70c3a3685c4a002509",
"profile_path": null,
"id": 1625287
}
]
},
"adult": false,
"backdrop_path": "/nlsNr1BEmRgRYYOO24NSHm6BXYb.jpg",
"production_companies": [
{
"name": "StudioCanal",
"id": 694
}
],
"release_date": "2018-01-11",
"popularity": 201.963181,
"original_title": "The Commuter",
"budget": 30000000,
"reviews": {
"total_results": 0,
"total_pages": 0,
"page": 1,
"results": []
},
"vote_average": 5.6,
"runtime": 105
}
We called their API to get the movies for each year:
#Get Results from TMDB for a specific year
def parseTMDBResults(year):
response = requests.get("https://api.themoviedb.org/3/discover/movie?api_key="+mykey+"&sort_by=popularity.desc&include_adult=false&include_video=true&page=1&primary_release_year="+str(year))
json_data = json.loads(response.text)
if debug:
print "Parsing page 1 from "+str(year)
parsePage(json_data, False)
currentpage=2
totpage=json_data["total_pages"]
for x in range(2, totpage):
response = requests.get("https://api.themoviedb.org/3/discover/movie?api_key="+mykey+"&sort_by=popularity.desc&include_adult=false&include_video=true&page="+str(x)+"&primary_release_year="+str(year))
json_data = json.loads(response.text)
print "Parsing page " +str(x) + " from "+str(year)
parsePage(json_data, False)
We retrieved all the movies. For each movie, we parsed the details and output it directly into a JSON file for later use. We are splitting the reviews into seperate files because we wanted to send them to seperate indexes.
Adding sentiment analysis (by Meaningcloud) on the fly
We also liked to have sentiment analysis performed on the reviews, so that we could search for ‘Positive’ reviews. Since Coveo does not offer sentiment analysis, we used MeaningCloud. We push the reviewtext content to MeaningCloud, which reports back the sentiment.
def getMovieDetails(date,id, update):
file = open("output/"+date+"_"+str(id)+".json","w" )
response = requests.get("https://api.themoviedb.org/3/movie/"+str(id)+"?api_key="+mykey+"&append_to_response=credits%2Ckeywords%2Calternative_titles%2Creviews")
json_data = json.loads(response.text)
#check for reviews
json_data["allreviews"]=""
if "reviews" in json_data:
reviewresults=json_data["reviews"]["results"]
else:
reviewresults=[]
if (len(reviewresults)>0):
reviewtext=""
#we have reviews
for results in reviewresults:
reviews= dict()
#copy parent data from the movie into the review record
reviews["parentid"]=json_data["id"]
reviews["id"]=str(json_data["id"])+results["id"]
reviews["url"]=results["url"]
reviews["title"]=json_data["title"]
reviews["release_date"]=json_data["release_date"]
reviews["content"]=results['content']
reviews["author"]=results['author']
reviewtext = reviewtext+"By: "+results["author"]+"<br>"+results["content"]+"<br>"
filerev = open("output/"+date+"_"+str(id)+"_"+results["id"]+"_review.json","w" )
filerev.write(json.dumps(reviews).encode('utf-8'))
filerev.close()
#We need to sent data to meaningcloud
if update and reviewtext:
#send to meaningcloud
print 'Calling meaningcloud'
urlmc = "http://api.meaningcloud.com/sentiment-2.1"
payload = "key=OURAPIKEY&lang=auto&txt="+reviewtext.encode('utf-8')+"&txtf=markup&doc=undefined&sdg=t&dm=s&egp=y&uw=y&rt=n"
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.request("POST", urlmc, data=payload, headers=headers)
sentiment= json.loads(response.text)
time.sleep(0.5)
sentimentMapping = { "P+": "Strong Positive", "P": "Positive", "ENU": "Neutral", "N":"Negative", "N+":"Strong Negative","NONE":"No sentiment" }
sentimentAgreeMapping = {"DISAGREEMENT":"Disagreement", "AGREEMENT":"Agreement"}
sentimentSubjMapping = {"SUBJECTIVE":"Subjective", "OBJECTIVE":"Objective"}
sentimentIronyMapping = {"IRONIC":"Ironic", "NONIRONIC":"Non-Ironic"}
if 'score_tag' in sentiment:
json_data["mysentimentvalue"]=sentimentMapping[sentiment['score_tag']]
json_data["mysentimentagree"]=sentimentAgreeMapping[sentiment['agreement']]
json_data["mysentimentsubj"]=sentimentSubjMapping[sentiment['subjectivity']]
json_data["mysentimentirony"]=sentimentIronyMapping[sentiment['irony']]
json_data["allreviews"]=reviewtext
if debug:
print "We have reviews, creating seperate file."
json_data["relatedartist"]=""
json_data["relatedsongs"]=""
#Scrape the webpage for songs and artists
if (json_data["imdb_id"]!=""):
json_data["relatedartist"],json_data["relatedsongs"]=parseIMDBPage(json_data["imdb_id"])
file.write(json.dumps(json_data).encode('utf-8'))
file.close()
As you can see above, we also parsed the IMDB Web Page (parseIMDBPage). We found out that the REST api does not offer the Songs and Artists of the soundtrack of the movie, but it was displayed on the IMDB Web Page. In order to get that, we scraped the IMDB Page with the following script:
def parseIMDBPage(id):
global meta
#Slow down the parsing
time.sleep(0.3)
try:
html = opener.open("http://www.imdb.com/title/"+str(id)+"/soundtrack")
bsObj = BeautifulSoup(html.read(),'html.parser')
content = str(bsObj)
except:
if debug:
print "Error at "+str(id)
content = ""
return "", ""
#print content
toparse=""
tosongs=""
matches = re.finditer(r'Performed by <.[^>]*>(.[^<]*)',content)
if matches:
for match in matches:
if (toparse==""):
toparse=match.group(1)
else:
if toparse.find(match.group(1))==-1:
toparse=toparse+";"+match.group(1)
#also add songs
matches = re.finditer(r'class=\"soundTrack .[^>]*>(.[^<]*) <br/>',content)
if matches:
for match in matches:
if (tosongs==""):
tosongs=match.group(1)
else:
if tosongs.find(match.group(1))==-1:
tosongs=tosongs+";"+match.group(1)
if debug:
print "IMDB "+str(id)+" Performed by: "+toparse+", songs: "+tosongs
return toparse, tosongs
We are now able to retrieve all the information which the API is offering us. This gave us around 250-300K movies in JSON files.
Step 2: Pushing the data
We have the JSON files, but they are still not in our index. So we needed to use our Push API to get it into our index.
Before we start pushing we first needed to create the necessary mapping fields into our Push Source. Each mapping reserves space to store the fields we needed for our UI (e.g., @mygenre, @myrelatedartist, @mymovieid).
Since we where uploading a lot of data, we used Batch API calls instead of single API calls. It takes single JSON and combines them into one big call, which is way more efficient.
Before we start pushing the data, we wanted to add some essential metadata to the JSON we got from the previous process, for example by adding the necessary Coveo fields, like documentId, date, clickableUri.
We also needed to provide a preview of the content so that people do not have to navigate to IMDB to read it.
Here is an example:
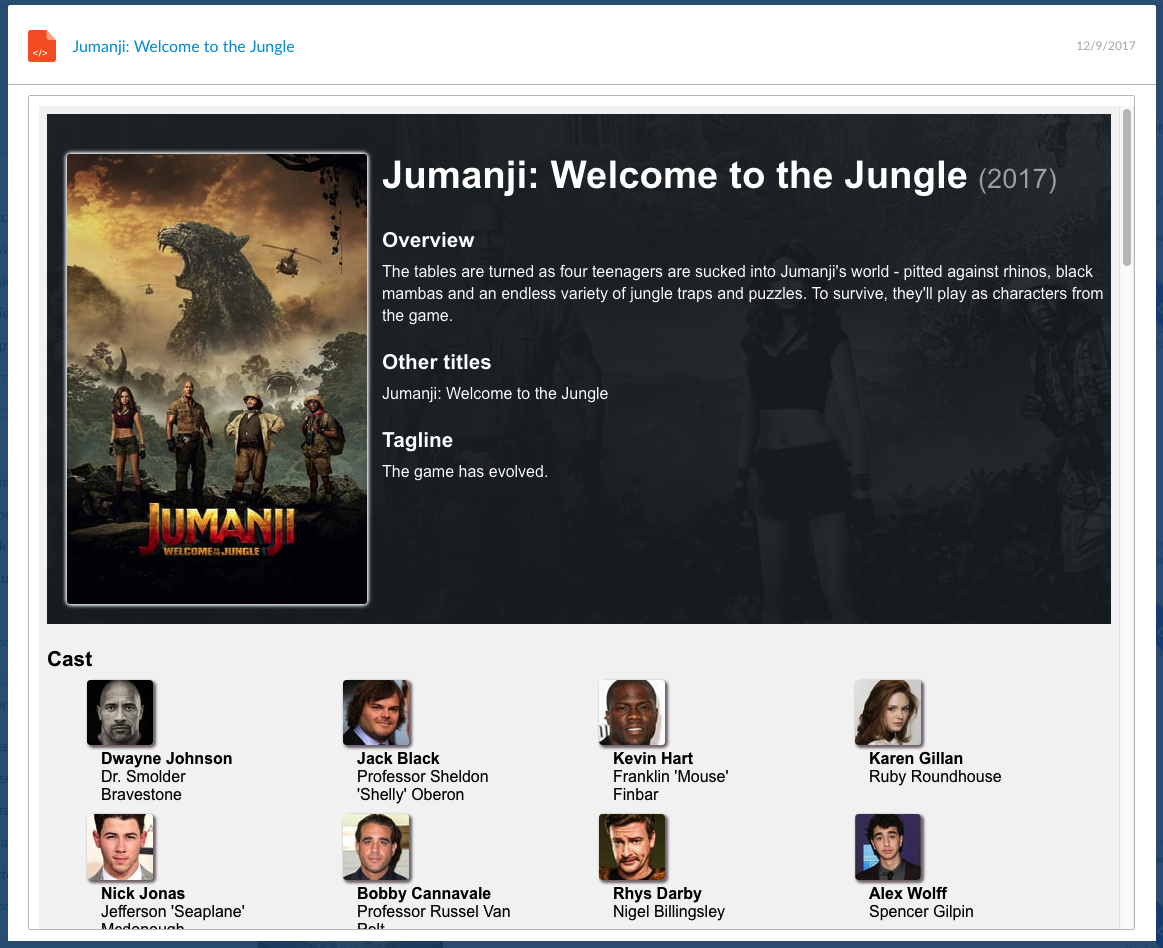 As you can see above, the HTML also included CSS to render the preview properly. All of that information was provided when creating the preview for the push call.
As you can see above, the HTML also included CSS to render the preview properly. All of that information was provided when creating the preview for the push call.
The final step was to encode the HTML properly:
#content contains the actual HTML text
compresseddata = zlib.compress(content.encode('utf8'), zlib.Z_BEST_COMPRESSION) # Compress the file content
encodeddata = base64.b64encode(compresseddata) # Base64 encode the compressed content
The script below builds up the JSON we needed.
def add_document(movie):
# Use movie id as unique identifier
meta=dict()
body=""
document_id=""
html= HTMLParser.HTMLParser()
#We have a normal movie
document_id = 'https://www.themoviedb.org/movie/'+str(movie['id'])
#build up all we need in the preview and in the metadata
# ...
#crews
crews=""
crewsfull=""
for crew in movie['credits']['crew']:
if allpeople.find(crew['name'])==-1:
allpeople=allpeople+crew['name']+';'
crews=crews+crew['name']+" as "+crew['job']+";"
if (crew['profile_path']):
crewsfull=crewsfull+"<li class='cast'><img class='castimg' src='https://image.tmdb.org/t/p/w66_and_h66_bestv2"+crew['profile_path']+"'><div class='info'><b>"+crew['name']+"</b><br>"+crew['job']+"<br></div></li>"
else:
crewsfull=crewsfull+"<li class='cast'><div class='noimage'></div><div class='info'><b>"+crew['name']+"</b><br>"+crew['job']+"<br></div></li>"
if crewsfull:
crewsfull="<ol class='castlist'>"+crewsfull+"</ol>"
# Build up the quickview/preview (HTML)
content = "<html><head><meta charset='UTF-16'><meta http-equiv='Content-Type' content='text/html; charset=UTF-16'></head>"
content += "<title>"+movie['title']+"</title>"
content += "<body>"
content += "<style>body { -ms-overflow-style: -ms-autohiding-scrollbar; background-color: #f4f4f4; color: #000; font-family: 'Source Sans Pro', Arial, sans-serif; font-size: 1em; -webkit-font-smoothing: antialiased; -moz-osx-font-smoothing: grayscale;}"
content += " .header { width: 100%; position: relative; z-index: 1;box-sizing:box}"
# ...
content += " </style>"
# ...
content += "<div class='header_info'><h3>Overview</h3></div>"
content += "<div><p class='over'>"+movie["overview"]+"</p></div>"
content += "<div class='header_info'><h3>Other titles</h3></div>"
content += "<div><p class='over'>"+movie["original_title"]+"</p></div>"
# ...
content += "</body></html>"
body=""
#Encode the HTML
compresseddata = zlib.compress(content.encode('utf8'), zlib.Z_BEST_COMPRESSION) # Compress the file content
encodeddata = base64.b64encode(compresseddata) # Base64 encode the compressed content
#For future use if we want to start pushing permissions
Permissions= json.loads('{"Perms":[{"PermissionSets":[{"AllowAnonymous": "True", "AllowedPermissions":[{"IdentityType":"Group", "Identity": "*@*"}], "DeniedPermissions":[]}]}]}')
meta["FileExtension"]=".html"
meta["Permissions"] = Permissions["Perms"]
meta["CompressedBinaryData"]= encodeddata
meta["connectortype"]= "Push"
meta["mytype"]= "Movie"
meta["myimage"]= movie["poster_path"]
meta["language"] = "English"
# ...
meta["mystatus"]= movie["status"]
meta["title"]= movie["title"]
meta["documentId"]= document_id
meta["clickableuri"]= document_id
meta["date"]= movie['release_date']
body=json.dumps(meta)
return body
The JSON is now ready! Our Push API can consume batches of 250Mb, so all we needed to do was to keep gathering the JSON until we reach this limit. Once hit, we can build our Request. This process is documented in our Push API Tutorial.
We first got a fileId and an uploadUri from our Push API, which will be used to upload the file to an Amazon S3 bucket. Then we let our Push API know that a new file is available.
def batchPush(jsoncontent):
#first get S3 link / fileid
coveo_fileid_api_url = configMovie.get_fileid_api_url()
coveo_headers = configMovie.get_headers_with_push_api_key()
print '\n--------\nBATCH, step 1: Call FileId for S3: POST ' + coveo_fileid_api_url
print 'Headers: ' + str(coveo_headers)
r = requests.post(coveo_fileid_api_url, headers=coveo_headers)
fileidjson=json.loads(r.text)
print "\nResponse from step 1: "+str(r.status_code)
#create batch json
print "Response for S3: fileid=>"+fileidjson['fileId']+", uploaduri=>"+fileidjson['uploadUri']
coveo_batchdocument_api_url = configMovie.get_batch_document_api_url(fileidjson['fileId'])
print '\n---------\nBATCH, setp 2: Upload to s3\n'
body = "{ \"AddOrUpdate\": [" + jsoncontent + "]}"
#send it to S3
r= requests.put(fileidjson['uploadUri'], headers={'Content-Type': 'application/octet-stream','x-amz-server-side-encryption': 'AES256'},data=body)
print '\nReturn from Upload call: '+str(r.status_code)
#push to source
print '\n---------\nBATCH, setp 3: Push call to Cloud\n'
r = requests.put(coveo_batchdocument_api_url, headers=coveo_headers)
print '\nReturn from Push call: '+str(r.status_code)
Not completely ready yet. We found out that the Movie Database creates a very nice interface with some color gradients based upon the movie picture. And (of course) we wanted to offer the same experience.
Coveo offers Indexing Pipeline Extensions. It enables the execution of a script for each item that will be indexed. Using those scripts, we can add additional metadata to the content before it is finally pushed to our index.
The script we used, will first check if the color was not already available in a DynamoDB table. If it was, the script retrieves it from there. Otherwise, it uses GM to color code the image. It then stores the retrieved values in a metadata field so that we can retrieve it in the UI.
The Indexing Pipeline Extension script looks like this:
import subprocess
import boto3
import re
db_client = boto3.resource(
"dynamodb",
aws_access_key_id="KEY",
aws_secret_access_key="ACCESS_KEY",
region_name="YOURREGION"
)
db_table = db_client.Table('ColorsFromImages')
def get_from_cache(key):
token_item = db_table.get_item(
Key={'name': key}
)
if ('Item' in token_item):
return token_item['Item']['value']
return None
def update_cache(key, value):
db_table.update_item(
Key={'name': key},
AttributeUpdates={'value': {'Value': value, 'Action': 'PUT'}}
)
def get_colors_with_gm(image_path):
image_name = image_path.replace('/', '')
curl_cmd = 'curl {}{} -o {} -s'.format(parameters['images_base_path'], image_name, image_name)
dl_file = subprocess.Popen(curl_cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
out, err = dl_file.communicate()
# Command line command and arguments
COMPRESS_CMDLINE = "gm convert {} -colors 6 -flatten HISTOGRAM:- | gm identify -format '%c' - | sort -r -n".format(image_name)
convert = subprocess.Popen(COMPRESS_CMDLINE, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
out, err = convert.communicate()
lines = re.sub('\\s', '', out)
lines = re.sub('srgb\\(', '', lines)
lines = re.sub(r'(\d+,\d+,\d+),\d+', '\\1', lines)
m = re.findall(r'\(\d+,\d+,\d+\)', lines)
image_colors = ' '.join(m)
update_cache(image_path, image_colors)
RM_CMDLINE = 'rm {}'.format(image_name)
convert = subprocess.Popen(RM_CMDLINE, shell=True)
return image_colors
try:
image_name = document.get_meta_data_value("myimage")[0]
log('image_name: ' + image_name)
image_colors = None
image_colors = get_from_cache(image_name)
if image_colors is None:
log('Getting from GM')
image_colors = get_colors_with_gm(image_name)
log('image_colors: ' + image_colors)
document.add_meta_data({
"mycolors": image_colors
})
except Exception as e:
log(str(e))
Read the next post The Elastic Search Demo, Part 2: Build the UI on how we built the UI.
Special thanks to my colleague Jérôme Devost who helped me build this!