In our previous post, we introduced the new architecture of the streaming data pipeline at Coveo, showing how it helps us achieve higher data quality, extensibility, scalability, and resilience. We also mentioned some of the challenges we faced. One of the most critical ones is cold starts in AWS Lambda. In this post, we will dive deep into this issue, share our approach to overcoming it, and showcase the results we’ve achieved along the way.
What is Lambda Cold Start?
Let’s first review the lifecycle of a Lambda execution environment. The diagram below illustrates the phases of a Lambda execution environment. It begins with the INIT phase, where Lambda downloads the code, sets up the runtime and runs any initialization code outside of the event handler. Once the INIT phase completes, the execution environment is ready to be invoked and to transition to the INVOKE phase. Since Lambda retains the execution environment for a period of time, it can handle multiple invocations before eventually being deleted (the SHUTDOWN phase) by the Lambda service.
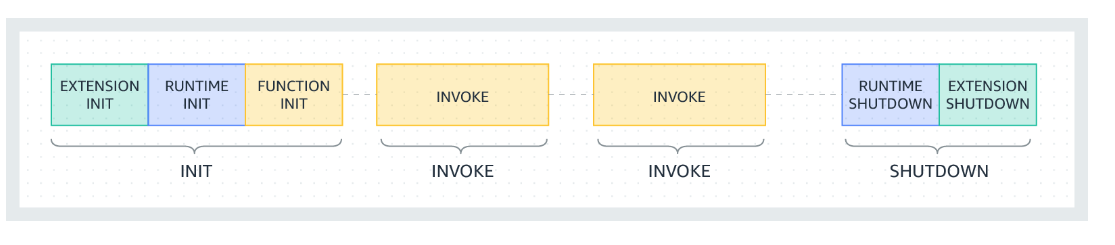 |
|---|
| Source: Understand the Lambda execution environment lifecycle |
When an execution environment has finished the INIT phase, we call it warm. In this state, an event can be processed immediately upon arrival, because the Lambda directly executes the handler code. On the other hand, if no pre-initialized execution environments are available to process incoming events, new environments must be created and initialized. This boot up process is referred to as cold start. Please note that while AWS excludes function initialization (executing code outside the handler) from the Cold Start duration, we consider initialization code execution as part of cold start in the following discussions, because initialization code is only executed when a new environment is created.
Why does the Lambda cold start matter for us?
According to the AWS Lambda documentation, cold starts only happen in less than 1% of invocations in a production environment. However, in real-time streaming data pipelines, where every millisecond is critical, cold starts have a substantial impact on performance and latency. As mentioned in our previous post, the traffic volume fluctuates due to various factors. During periods of low traffic, some execution environments become idle and are eventually deleted by AWS Lambda. When the traffic picks up again, more invocations need to run concurrently to accommodate the surging traffic. These additional invocations require new execution environments to be warmed up, leading to increased latency in event processing, which in turn affects the overall end-to-end latency — our most important performance metric for the streaming pipeline.
To understand the exact cold start duration, we analyzed the CloudWatch logs generated by Lambda. The logs provide important metrics like start and end times, execution duration, memory usage, and billed duration etc. They also include an INIT_REPORT log showing the duration of the INIT phase. The following screenshot shows an example initialization process from CloudWatch logs. We were surprised to find that the INIT phase in our Lambada sometimes took more than 20 seconds to complete. The worst part is, the INIT phase was executed twice, leading to more than 30 seconds in total for the execution environment to be fully ready to process events. After investigations, we learned that Lambda enforces the 10 seconds limit of the INIT phase (documentation). If the INIT doesn’t complete within 10 seconds, the initialization will be retried during the first function invocation. This means that when an invocation encounters a cold Lambda execution environment, there’ll be a delay of at least 10 seconds to process it. In contrast, when an execution environment is warm, the duration of processing a request is under 200 milliseconds. The significant extra time caused by cold starts severely impacted the overall performance of the streaming data pipeline.
 |
|---|
| CloudWatch Log from a Lambda invocation |
It’s also worth noting that cold start times vary depending upon the selection of programming language. Pluralsight published a blog comparing performance of the AWS Lambda by language, and one key finding is that statically typed languages like Java and C# have 100 times longer cold start times than Python and Node.js. Unfortunately, all our Lambda functions are written in Java, which exacerbates the cold start issue.
How can we optimize?
1. Rewrite Lambda functions in a different language
Rewriting the functions in a language like Python will probably mitigate the impacts of cold starts. However, it is not an option for us because rewriting everything in a different language is not only costly but also time-consuming. When we originally developed these Lambda functions a few years ago, Java was the best choice due to our team’s strong expertise in Java. Most importantly, we were able to write less code in Lambda functions by reusing the Java frameworks we already built.
2. Provisioned Concurrency
Provisioned Concurrency is an AWS feature developed to address the cold start challenges in time-sensitive use cases. It allows you to have a set number of pre-initialized execution environments that are ready to instantly respond to incoming events, eliminating the INIT phase from the event handling process. While this sounds like a perfect solution for the cold start issues we were facing, it comes at a cost. After calculating the additional expenses based on traffic volume and Lambda configurations, we found that these costs were substantial, nearly doubling our existing Lambda costs. Before conducting a comprehensive cost-benefit analysis, we decided to first explore free optimization options.
3. Optimize the initialization code
As mentioned earlier, the initialization was being executed twice because the INIT phase exceeded the 10-second timeout. If we could reduce the duration to under 10 seconds, we would cut our cold start times significantly, almost in half. This became our top priority.
The init phase can be broken down into three sub phases: downloading code, starting runtime and executing initialization code. By measuring the duration of the initialization code execution, we discovered that more than 80% of the INIT duration was contributed by the execution of the initialization code.
 |
|---|
| Lambda Init Phase |
The following code shows the handler implementation we were using. The constructor EventEnrichmentHandler is executed during the INIT phase, and its main purpose is to create reusable objects that don’t need to be created with every invocation. We also added measurements around each object creation. We were surprised to see how much time it spent on creating AWS service clients. For example, creating an S3Client alone can take up to 2 seconds. Additionally, retrieving a secret from AWS Secrets Manager sometimes takes 1 second. These delays seem small individually, but together they add up to more than 10 seconds.
public class EventEnrichmentHandler
implements RequestHandler<KinesisEvent, StreamsEventResponse> {
// Initialization Code. Executed during INIT phase
public EventEnrichmentHandler() throws Exception {
try {
// Creating AWS S3 client
long start = System.currentTimeMillis();
S3Client s3Client = S3Client.builder().build();
logger.info("Took {} ms to create s3Client", System.currentTimeMillis() - start);
// Creating AWS DynamoDB client
start = System.currentTimeMillis();
DynamoDbClient dynamoDbClient = DynamoDbClient.create();
logger.info("Took {} ms to create dynamoDbClient", System.currentTimeMillis() - start);
// Creating Secrets Manager client
start = System.currentTimeMillis();
SecretsManagerClient secretsManagerClient = SecretsManagerClient.builder()
.region(Region.of(SECRET_REGION))
.build();
logger.info("Took {} ms to create secretsManagerClient", System.currentTimeMillis() - start);
// Creating CloudWatch Client
start = System.currentTimeMillis();
CloudWatchAsyncClient cloudWatchClient = CloudWatchAsyncClient.builder().build();
logger.info("Took {} ms to create cloudWatchClient", System.currentTimeMillis() - start);
// Getting a secret from Secrets Manager
start = System.currentTimeMillis();
String secret = secretsManagerClient.getSecretValue(GetSecretValueRequest.builder()
.secretId(SECRET_ID)
.build());
logger.info("Took {} ms to get secret", System.currentTimeMillis() - start);
// Creating Other Objects
ObjectA a = createObjectA();
ObjectB b = createObjectB();
ObjectB c = createObjectB();
} catch (Exception e) {
sendNotification()
throw e;
}
}
// Handler Code. Executed during Inovcation phase
public StreamsEventResponse handleRequest(KinesisEvent input, Context context) {
// Event Processing logic
}
}
We initially only specified the bare minimum when creating AWS service clients, as the sdk is smart enough to automatically determine most of the configurations. After digging into the behaviors of how service clients are initialized, we realized that we could actually save time by specifying certain parameters. For example, when no credential provider is specified, the AWS sdk goes through a predefined sequence to locate credentials. The order of checking is: Java system properties, environment variables, web identity token from AWS Security Token Service, shared credentials and config files, ECS container credentials and EC2 instance IAM role-provided credentials. If we specify a credential provider, we can avoid the overhead of this sequential search process. Similarly, if a region is specified when building the client, the sdk doesn’t have to spend time figuring out the region where the lambda is running.
Additionally, AWS provides three http clients, and the default for asynchronous clients is ApacheHttpClient. We compared the three http clients and found that UrlConnectionHttpClient is sufficient for our use case. It is more lightweight and thus loads more quickly than the default Apache-based HTTP client.
In the end, our S3 client creation looks like the following. We made this change to all the service clients in the code.
S3Client s3Client = S3Client.builder()
.httpClientBuilder(UrlConnectionHttpClient.builder())
.region(Region.of(SystemFlags.AWS_REGION.getValue()))
.credentialsProvider(EnvironmentVariableCredentialsProvider.create())
.build();
4. Reduce the package size
As the INIT phase starts with downloading code, the size of the code package directly affects the download time. We reviewed the direct and transitive dependencies and identified several that can be excluded. For example, as we switched to UrlConnectionHttpClient for the AWS service clients, we removed the other two http client libraries from the AWS java sdk. The reduction in unnecessary dependencies helped shrink the package size, decreasing the time spent on downloading the code.
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>s3</artifactId>
<exclusions>
<exclusion>
<groupId>software.amazon.awssdk</groupId>
<artifactId>netty-nio-client</artifactId>
</exclusion>
<exclusion>
<groupId>software.amazon.awssdk</groupId>
<artifactId>apache-client</artifactId>
</exclusion>
</exclusions>
</dependency>
5. Avoid cross-region interactions with AWS services
When we compared the cold start time for the same Lambda deployed in different regions, we noticed that one region had a shorter cold start duration than the others. After investigations, we found that this Lambda was retrieving a secret from the Secrets Manager located in the same region, while others were reading from a different region. Cross-region data access added additional latency. To avoid this issue, we replicated the secret across all the regions where our Lambdas were deployed, and ensured that each Lambda retrieves the secret from its own region. AWS Secrets Manager allows one secret to be replicated across multiple regions, which not only reduces the latency on secret retrieval, but also keeps the secret value synchronized across all regions.
After implementing the above changes, we saw a significant reduction in cold start times. The frequency of double initialization occurrences was also reduced. The figure below shows maximum Lambda Duration before and after deploying the optimized code. The maximum duration was significantly dropped. Before the optimization, the maximum duration can reach up to 65 seconds, and after optimization, the maximum duration falls into a much lower range.
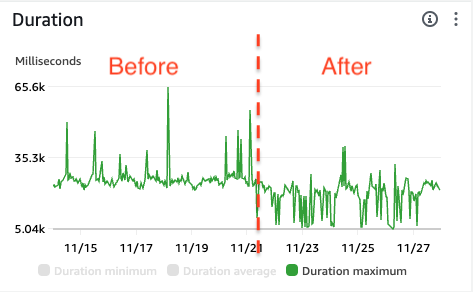 |
|---|
| Maximum Duration After Code Optimization |
6. SnapStart
We saved the best for last! SnapStart, as the name suggests, is a mitigation for cold start. It is a feature launched by AWS in 2022, to improve the startup time for Java applications. The best part - it’s free! With SnapStart, the execution environment is initialized when we publish a function version. Then it takes a snapshot of the memory and disk state. When an execution environment needs to be created, the snapshot is retrieved from a cache and restored. Compared to the full initialization process, using snapshot only requires restoring a snapshot, and the duration is largely reduced. In our case, using SnapStart cut the initialization duration down to just 10% of the full initialization time, as shown in the first screenshot below. The second screenshot shows the maximum duration before and after enabling SnapStart. We can see that this value was reduced drastically.
 |
|---|
| Logs for INIT phase after SnapStart is Enabled |
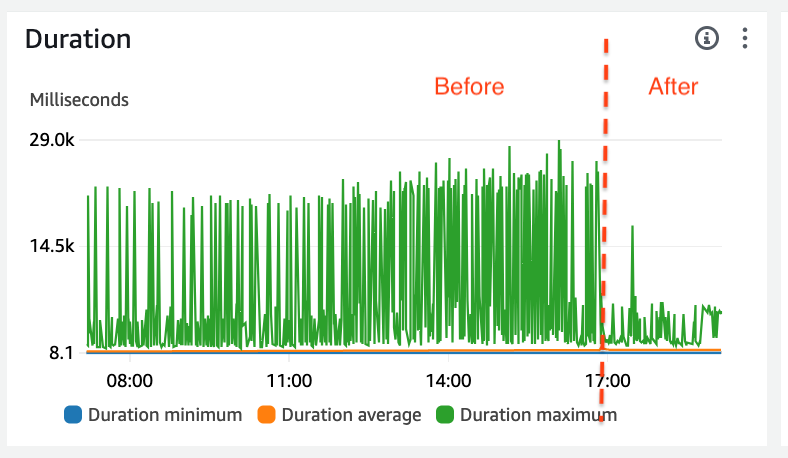 |
|---|
| Max Duration after SnapStart is Enabled |
What did we learn about SnapStart?
Although the improvements from all the optimizations were successful, and the decision was made not to revisit the costly option of Provisioned Concurrency, a few pitfalls were encountered, particularly with the use of SnapStart.
1. DNS cache should be disabled
By default, Java has 30 seconds of DNS cache Time-To-Live (TTL). If TTL isn’t set explicitly to 0, Java will use the cached IP address for 30 seconds. Initially we didn’t disable the DNS cache in the code, and everything worked fine for about a month, until we were notified of constant errors in Lambda. The Lambda function started throwing an error, and due to our retry configuration, it kept retrying failed requests infinitely. This completely blocked the data pipeline as the Lambda was not able to handle new events. After hours of investigation, we found that the IP address of a resource had changed since the snapshot was taken. When the Lambda was invoked, it used the stale IP cached from when the snapshot was taken, causing the connection failure. To avoid this issue, we disabled DNS caching by configuring TTL values to be 0.
java.security.Security.setProperty("networkaddress.cache.ttl", "0");
java.security.Security.setProperty("networkaddress.cache.negative.ttl", "0");
2. Lambda function versions should be managed properly
Since SnapStart only works with published versions of Lambda, we started publishing versions after enabling SnapStart (before that we had been only using the unpublished $LATEST version). As we didn’t delete old versions (and Lambda doesn’t provide a configurable feature to delete old versions), we ended up with over 50 versions of a single Lambda function. We were unaware that all these versions were being periodically re-initialized by the Lambda service until we received a notification about an initialization failure for a very old version. Although this behavior was mentioned in this documentation under SnapStart pricing section, we overlooked it after seeing the statement “there’s no additional cost for SnapStart”. To mitigate this issue and to reduce costs associated with re-initializations, we created the following bash script to keep only the latest two versions of Lambda function. The previous version is kept in case we need to roll back. This script is automatically triggered after a new version is published.
#!/usr/bin/env bash
set -e
function=$1
max_version=$2
for version in $(aws lambda list-versions-by-function --function-name ${function} --query 'Versions[?Version!=`"$LATEST"`].Version' --output text);
do if [[ $version -le $max_version ]]
then
echo "deleting ${function}:${version}"
aws lambda delete-function --function-name ${function} --qualifier ${version}
fi
done
Conclusion
In this blog post, we shared our journey of overcoming cold starts in our Lambda functions. Through a combination of strategies, including optimizing initialization code, reducing package size, and leveraging AWS SnapStart, we successfully reduced Lambda duration and improved the performance of our streaming data pipeline. Although this journey was not smooth and we had a few pitfalls, we learned valuable lessons and strengthened our knowledge of serverless architecture and AWS Lambda in particular. We hope this blog helps developers facing similar challenges in their architecture. We are also looking forward to continuing improving our real-time pipeline and sharing with the community.
If you’re passionate about software engineering, and you would like to work with other developers who are passionate about their work, make sure to check out our careers page and apply to join the team!