Do you want to have better and faster search results in your Coveo-powered catalog search pages? You can do it by creating an indexing pipeline extension (IPE) that identifies and stores all the variations of your partial SKU values.
Making a good user experience when dealing with parts, pieces, or any complex product catalog, is not an easy task. Sometimes, the complexity of the catalog is carried over to the user experience, affecting not only the relevance but ultimately conversions on your website.
Now, a retail or occasional customer might be willing to search by keyword and sift through the results, but commercial buyers are more likely looking for a specific product to order or reorder. And, they expect rapid retrieval from these large data sets, even if they don’t use the complete product ID, or SKU, when searching.
While you could simply make the SKU field searchable with wildcards, you can make the response time up to 10 times faster by using SKU decomposition.
What is SKU Decomposition, anyway?
Suppose one of your products has a SKU value of SJSH9-000-3K, but your buyers don’t always enter the full value. They might only enter SJSH9, for example, since it represents the category of product that they are looking for. You can identify character sequences in the SKU and link them to the products containing the partial values. For the example above, some variations of the SKU value are: S, SJ, SJS, SJSH, SJSH9, 0, 00, 000, 3, 3K. This slicing and dicing of the SKU value is called decomposition.
By working out the list in advance and storing it in the index, your Coveo-powered search interface will be able to find and surface relevant results without spending precious query time scanning the contents of all possible matching items.
Field Management
If your catalog data is well structured and the SKU field already exists, then all you need to do is create a new field and map it to the SKU field. You can do this from the Coveo Platform Administration Console using the Add field option from the “Fields” menu of the Content section. Make sure you select the ‘String’ Type and check the ‘Multi-Value Facet’ and ‘Free text search’ checkboxes, as highlighted in the screenshot below. In this example, our new field is called product_partial_match.

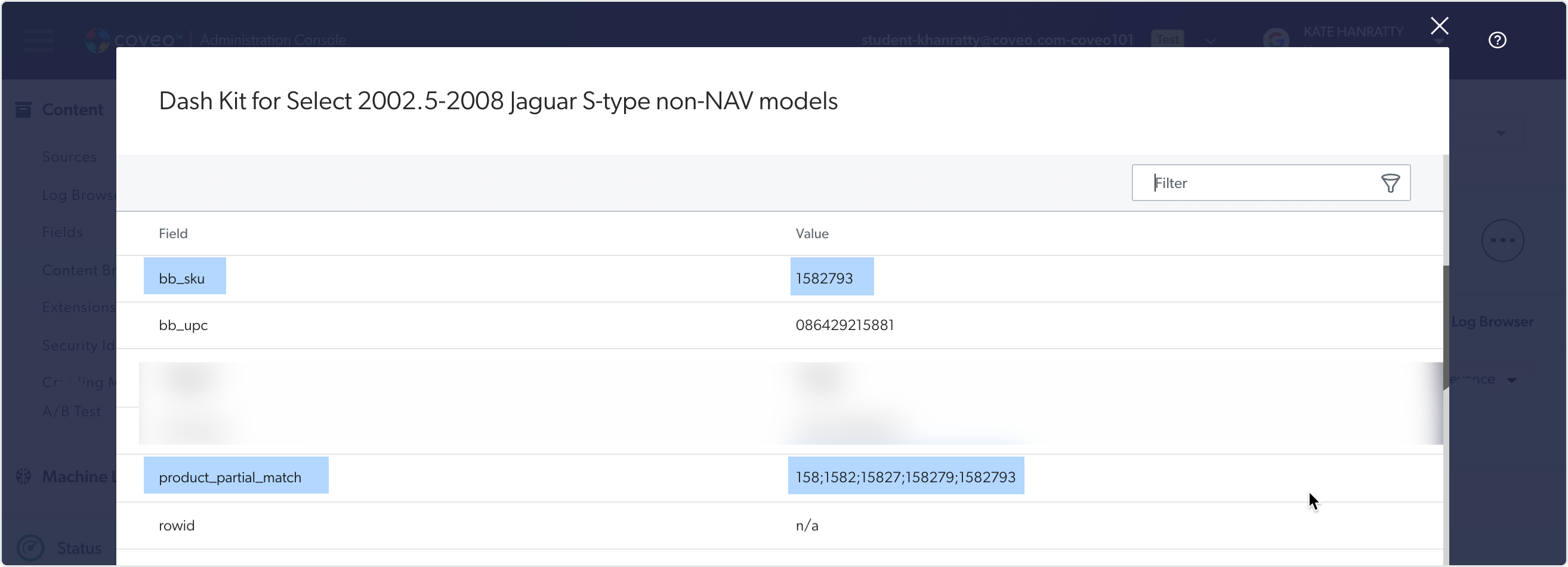
Then, you can map this field to your SKU metadata field for the catalog source. In the screenshot below, the new field product_partial_match is associated with the existing field for the actual SKU value: bb_sku.

Check out our documentation for more details on how to add a mapping rule.
For sources that use the Push API you can take another approach. If you compute the list of partial SKU values and submit them as another field in the index, then no indexing extension is required. Just make sure that your field has the characteristics described here: ‘String’ type, ‘Multi-Value Facet’, and ‘Free text search’.
If your data source doesn’t already have a single metadata field that holds the SKU, you should explore ways to standardize the data. Alternatively, you can add configuration to do SKU decomposition on each field that should be inspected and parsed.
Indexing Extension
The key to making this work is to add an extension to the indexing process that will examine the SKU field, identify all the variations of the partial (sequential) values, and store them in the index. The response time gains come from having all the variations ready for comparison, rather than having to expand the wildcard at search time.
If you have never added an indexing pipeline extension, you access it from the “Extensions” menu item in the Content section of the Administration Console. You can learn more about this in our documentation on managing indexing pipelines.

Add a name and description for the extension. Then, paste the following python code snippet into the Extension script box, as shown in the screenshot above.
def get_safe_meta_data(meta_data_name):
safe_meta = ''
meta_data_value = document.get_meta_data_value(meta_data_name)
if len(meta_data_value) > 0:
safe_meta = str(meta_data_value[-1])
return safe_meta
def splitSKU(meta):
keywords = meta.split()
searchableKeywords = []
for keyword in keywords:
print(keyword)
letters = list(keyword)
searchableKeyword = []
previousChar = ""
for letter in letters:
previousChar += letter
# starting at 3 characters
if (len(previousChar) > 2):
searchableKeyword.append(previousChar)
searchableKeywords += searchableKeyword
return ';'.join(searchableKeywords)
def splitSpace(prod):
parts=prod.split(' ');
newparts = '';
for nr in range(1,len(parts)):
newparts+=prod.replace(' ','',nr)+';'
return newparts
try:
sku_meta = 'original_sku_field'
sku_field = 'new_partial_sku_field'
sku = get_safe_meta_data(sku_meta)
splitSpace = splitSpace(sku)
split_sku = splitSKU(sku)+';'+splitSpace
log('split_sku: ' + split_sku)
document.add_meta_data({sku_field: split_sku})
except Exception as e:
log(str(e))NOTE: we strongly recommend using a minimum of 3 characters for SKU decomposition.
To get this code to access your fields, set sku_meta to your original or existing SKU field and sku_field to the new field you created to hold the list of partial values. In our example, we used:
sku_meta = 'bb_sku'
sku_field = 'product_partial_match'Tying it together
After you save the new extension, you must associate it to the indexing source. This is similar to the field mapping process: select your catalog source in the Content section of the Administration Console, then from the “More” menu item, select the ‘Manage Extensions’ option.
Select the extension you created earlier and then adjust the settings for applying the extension on the source items. For the “Stage” option, choose ‘post-conversion’. We recommend that you choose the ‘skip extension’ option for the error action and apply to all items since the reject option will eliminate the document from the index. These are the options highlighted in the screenshot below.

For these changes to be applied, you will have to reindex your catalog data, or re-push if your source is populated using the PUSH API.
Check your work
You can verify that the partial match searching is functioning correctly by reviewing the logs for the reindexing process to see whether there have been any errors. These are available from the “Log Browser” menu in the Content section. The list of partial SKU values is built up during the post-conversion stage of document processing, so you can narrow the search to the ‘Applying extension’ option in the “Stages” facet.
A successful application of the indexing extension looks like this:
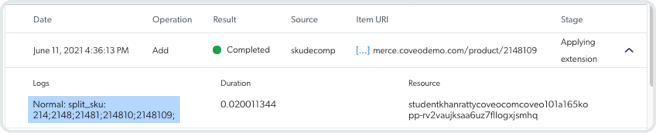
A failure to apply the indexing extension might look like this:

In this example, the SKU values are strictly numeric, but the code to parse the SKU was expecting a string, not a number. Not to worry, though, the extension script shown above already converts the numeric SKU to a string.
You can also use the content browser to look at the properties of an indexed item to confirm that the SKU value gets indexed and then decomposed into the variations stored in your new field. This is highlighted in the image below.
Conclusion
The methods outlined in this post can help you deliver more relevant search results faster if your users enter partial SKU values. In addition to the processing gains, the pipeline extension can be applied to multiple sources which allows you to be more consistent across your catalog sources.
Want to get your hands dirty and try this yourself? Check out our trials site!
Do you like working on this type of challenge? Check out our careers page.