Over the years I’ve been at Coveo, I’ve often had to explain the different technological stacks we use and their associated teams. The best way I’ve found to understand the whole intelligence platform was to follow a recommendation or search request life cycle, so let me take you on that journey.
It starts with a simple UI, either as a simple recommendation or a search box rendered in the browser.
Behind these pixels, there are multiple teams working hard to make sure it looks and works great. At the core, we have Search UI (TypeScript, React, JavaScript, Go, Terraform, Kubernetes), a team that is responsible for developing the Coveo UI library that our clients use to integrate Coveo into their systems. They are also developing a WYSIWYG application that allows non-developer customers to customize their UI integration, and most recently, the team is creating a new backend service that will allow customers to host and bootstrap the creation process of the UI.
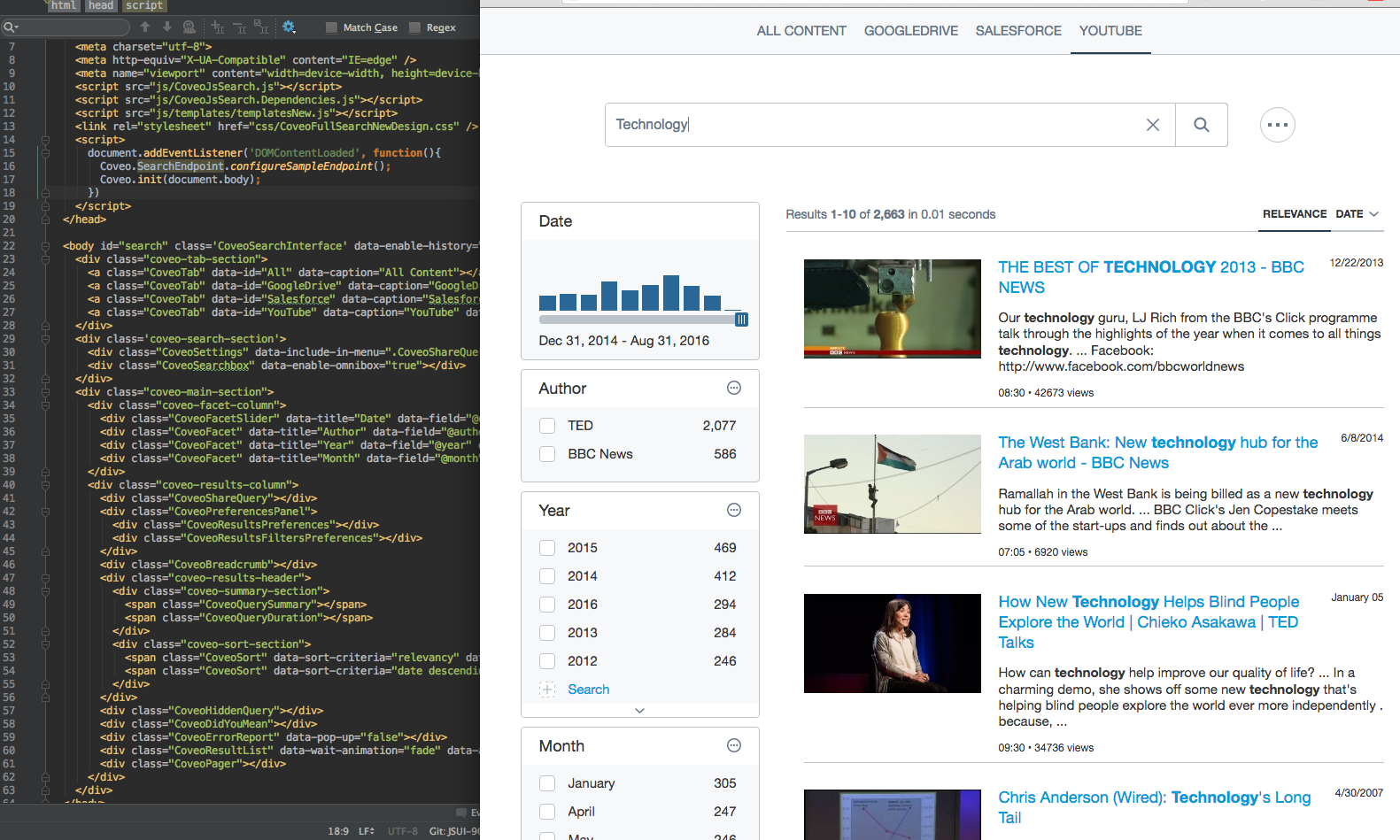
Then, the following teams help integrate the UI and adapt Coveo inside multiple use cases: Salesforce Integration (TypeScript, JavaScript, Salesforce), Sitecore (C#, Typescript, React), Commerce (Java, Spring Boot, AWS, Terraform, Kubernetes, Docker, Typescript, React, Redux, SCSS) , and ServiceNow (C#, JavaScript). Each team’s goal is to fully integrate Coveo inside their associated use case and make sure it’s convenient and easy to use.
These teams work closely with our UX (Sketch, InVision, Adobe Suite, Confluence, Google Drive, LucidCharts) and Demo (JavaScript, TypeScript, Python, Go, AWS, Salesforce) teams. The UX team’s goal is to design the user’s journey across all Coveo products based on various user research and design activities, in collaboration with PMs. They monitor and validate the development of new features to ensure simple, usable, and appealing user interfaces.
The Demo team’s goal is for its members to become Coveo product experts, so that they can design and build the best representations of what we can bring to our customers.
That’s it from the perspective of the client’s browser, but there’s a lot more to the story. When a customer visits a page with a recommendation or a search page, a query is sent to our servers. Coveo is hosted on AWS. To maintain those servers, we separate the workload across three teams: Cloud Infra, Cloud Ops, and Platform Foundation.
The Cloud Infra (Kubernetes, Terraform, Elasticsearch/OpenDistro, Prometheus, Puppet, AWS, Python) team provides and maintains the base infrastructure needed to run Coveo’s Cloud services.
The Cloud Ops (Python, Jenkins, AWS, Kubernetes) team manages the Cloud Production environments 24/7 to ensure their best performance and uptime. They also perform rollouts of some workloads, manage Ops requests, and oversee AWS costs.
The Platform Foundation (Java, Spring Boot, Spring Cloud, AWS, Terraform, Kubernetes, Docker) team’s mission is a bit different. They implement and maintain solutions throughout the technology stack for the core functionalities of a world-class SaaS platform such as observability, high availability, fault-tolerance, service discovery, internet gateway, and authentication.
Once the request is received on our infrastructure, it is routed to the Search API (Scala, Kinesis, RDS, Redis, Terraform, Kubernetes, Elasticsearch) team. They orchestrate all of Coveo’s micro-services that drive recommendations and searches, which are vital to our clients’ businesses. They also empower our customers’ administrators with a programmable query transformation system (QPL).
From a high-level perspective, the Search API uses indexed content and machine learning models to find the relevant information to answer the request. Behind these concepts, multiple teams are responsible for surfacing this information efficiently.
From an index perspective, there are three main teams: Index, Index Infrastructure, and Indexing Pipeline.
The Index (C++, Python, Java, AWS) team is responsible for the core index/search technology used at Coveo. This team also manages the Java Index and Field services.
The Index Infrastructure (C++, Python, Docker, Kubernetes, Terraform, CMake, Jenkins) team implements, deploys, and monitors solutions to improve and scale our customers’ indexing capabilities.
The Indexing Pipeline (C++, Python, Java, Docker, Kubernetes, Terraform) team is responsible for the backend pipeline that processes every document to make them ingestible by the Index Service. This includes carrying the documents from one step to the next and transforming them (conversion, indexing pipeline extensions, etc.). This team is also responsible for the Java Extension Service.
Overall, these teams’ purpose is to surface content to a search query, and to do it as quickly as possible. To move the data from our customers’ repositories to our index, we will need the help of multiple other teams: Connectors (C#, .Net, .Net Core, Terraform, MySQL), Salesforce Connectivity (C#, Scala), Connectors Infrastructure (Java, .Net Core, Terraform), Security Cache (C++, Java, Python), and Sources (Java, Spring, Terraform, AWS, Elasticsearch, Kubernetes, Docker).
The Connectors team designs, implements, maintains, and deploys Connectors which allow our clients to configure and crawl various content sources to retrieve data, metadata, and permissions.
The Salesforce Connectivity team develops and maintains our solution that crawls all the needed data, schema, metadata, and permissions from the Salesforce Platform. Half a billion items are crawled each week by this connector.
The Connectors Infrastructure team designs, implements, deploys, and monitors solutions to improve and scale the infrastructure supporting Coveo’s secure content crawling capabilities.
The Security Cache team develops and maintains the modules used to enforce a secured search, i.e., to quickly and accurately determine which users can see which pieces of information when a query is performed.
The Sources team develops and maintains APIs that allow clients to customize the content they wish to index, as well as APIs that allow them to push their content to our infrastructure.
We’ve covered a request coming from the UI, going into our infrastructure, and getting routed by the Search API to the index which matches some content. What about all of the personalization and machine learning? Well, the Search API also calls our machine learning microservices and merges everything together. Thus, like the index, we need a way to create these machine learning models. This is the job of multiple Machine Learning (Scala, Spark, Python, PyTorch, TensorFlow, Scikit-learn, EMR, Kinesis, DynamoDB, Lambda) teams, the Machine Learning Backend (Java, AWS, Kubernetes, Spring, Terraform) team, and the Usage Analytics (Java, Kinesis, Snowflake, Redshift, Terraform, Tableau, DynamoDB, MySQL) team.
We have multiple Machine Learning teams that are developing machine learning algorithms and NLP models to learn from users’ interactions and documents’ contents to produce advanced functionalities such as automatic relevance tuning, query suggestions, recommendations, semantic search, question answering, automatic categorisation, and more.
The Machine Learning Backend team has developed a platform to build and serve machine learning models and keep them performing at a high level, even while their usage is doubling every year.
The Usage Analytics team collects signals about user interaction points with Coveo products and provides our customers with the ability to monitor and understand what is going on with their application so that we can help them optimize it. This information is also used by the machine learning algorithms.
So ultimately, with the content from the index and our machine learning models, we are able to answer the initial request! Hooray!
There are some other important teams at Coveo that are omnipresent, even if they aren’t part of the query path. Here are some examples:
The Administration Console (JavaScript, TypeScript, React/Vapor, Redux, Nightwatch, Jest, CSS/SASS, Jenkins, HTML5) team provides customers with an administration console that allows them to configure, tune, and monitor their Coveo application using a single point of service.
The Dev Tooling (Python, Go, Terraform, Jenkins) team develops deployment tools to improve the day-to-day efficiency of our other development teams. They facilitate development in a DevOps mindset.
We also have several specialist teams whose role is to support all of the other teams:
The QA team validates all changes prior to their deployment and assures the general quality of all production features.
The Documentation (Markdown, Jekyll, Ruby, JavaScript, Python, TypeScript) team delivers accurate, complete, concise, easy to use, and well-written documentation to help Coveo customers, partners, and employees understand and leverage our products.
And our 3 security teams:
Security - Compliance & Effectiveness - Red (Python, Veracode, Snyk) automates compliance validation and auditing, educates the development teams about best compliance practices, and executes penetration testing.
Security - Defense & Systems - Blue (Python, Kubernetes, Terraform, Elasticsearch, Prometheus, Java / Scala, C#, AWS, Docker) builds and deploys security applications and automates manual processes from cloud privileges to the Software Development Lifecycle. They defend against attackers and work constantly to improve our security posture.
Security - Governance & Risks - Green is a governance-driven team. They evaluate security and privacy risks, manage relationships with providers and customers’ security teams, and maintain internal information Security Programs and Policies.
Finally, the Solution Architect team (Coveo, Sitecore, Salesforce, ServiceNow, Google Tag Manager, JavaScript, Python, LucidCharts) is a business-oriented team which empowers integrators through a deep knowledge of the product and years of field experience. Their clients are both external (customers, end users, and partners) and internal (sales, success, support, and training).
That’s it! It takes all of these teams working together to make software like ours here at Coveo. I hope that all this information helps you understand all of the work that goes into something as simple as some recommendations or a search box.
If you are interested in joining Coveo R&D and helping us solve these challenges together, you can check out jobs.coveo.com.