
If you’re one of the many passengers on the deep learning hype-train (welcome aboard), you’ve at some point almost certainly experienced the great confusion of having to choose a deep learning framework.
If you’re trying to choose a framework, or maybe re-evaluating your choices, I might be able to help!
I’ve done a lot of the leg work for you, having made a pretty comprehensive report on the state of deep learning frameworks that compares their strengths and weaknesses.
I compared these frameworks based on three categories that we value most (Support & Community, API, and Platform), and used (as much as possible) quantitative measures to compare each one. A bit of warning: this is a long post, so you can always skip ahead to the overall results if you’re impatient.
Table of Contents
- Methodology Summary
- Frameworks in this Comparison
- Overall Results
- Round One: Support & Community
- Round Two: API & Internals
- Round Three: Platform
- Discussion
Match Rules: Methodology Summary
Each framework was scored on three categories, each with its own sub-criteria:
- Round One: Support & Community
- Sponsor — How is this framework funded?
- Activity — Is it actively developed?
- Ecosystem — Are people using it?
- Round Two: API & Internals
- Sym/Dyn Graph Building — Does the framework support dynamic, or old-school symbolic graph computational building?
- Numerics — What numeric backend is being used? Is it actively developed? Easy to use?
- OOTB NN Ops — What are the out-of-the box neural network layers and operations that are supported?
- Round Three: Platform
- Scalability — Does this framework support (easy-to-use) multi-machine training/prediction?
- Languages — Are there many, mature, language bindings?
- OS Support — Are many OS environments supported?
- AWS Support — Is it easy to use in the AWS cloud?
- ONNX Support — Can we serialize models to the ONNX format?
“How are each of these criteria measured?!” I hear the throng of data-hungry quants cry out in anguish and anticipation — don’t worry, I go into details for each category’s methodology in sections to come 🤓.
Without further ado, let’s meet the frameworks.
The Belligerents: Frameworks in this Comparison
Say hello to our frameworks! This isn’t an exhaustive list of all deep learning frameworks in existence™, but it’s a pretty comprehensive list of frameworks that have either (1) some sort of following or (2) interesting properties.
| Framework | Primary Association | Year of First Public Release |
Comments | |
|---|---|---|---|---|
 |
BigDL | Intel Analytics | 2017 | Big data focus (Spark, Hadoop, & friends). |
 |
Caffé | Berkley’s BAIR | At least 2014 | Very large model zoo. |
 |
Caffé2 | Facebook’s FAIR | 2017 | Used at Facebook in production. |
 |
Chainer | Preferred Networks, Inc | 2015 | Uses dynamic auto-differentiation. 🎉 |
 |
CNTK | Microsoft Research | 2016 | Very good Azure support (predictably). |
 |
Deeplearning4J | Skymind.ai | 2014 | Just released a 1.0 in beta. |
 |
Apache MXNet | Apache Software Foundation | At least 2015 | AWS “framework of choice”. |
 |
Neon | Intel Nervana | 2015 | Designed with speed as a primary focus. |
 |
PaddlePaddle | Baidu Research | 2016 | Major version still 0.x. Much of the example documentation is in Mandarin. |
 |
PyTorch | Facebook’s FAIR | 2017 | Still 0.x, but 1.0 is coming very soon. Also, dynamic auto-diff! |
 |
TensorFlow | Google Brain | 2015 | GCP Support. |
 |
Torch | Ronan, Clément, Koray, & Soumith | 2002 | Lua, Started out with S. Bengio et al. |
 |
Theano | MILA/LISA | At least 2008 | No longer supported by MILA. |
A Notable Omission
A perhaps noticeable omission in this list is Keras, a framework headed by François Chollet, whose API is easy to use and aims to be a sort of lingua franca, fronting a TensorFlow, Theano, CNTK, or MXNet backend0. Keras got excluded from this comparison for a couple of reasons, not least of which are:
- Most of the criteria here would change depending on what backend Keras is using.
- All of Keras’ stable and experimental backends are contestants in the showdown.
If you’re currently evaluating Keras as a solution and want to use this guide, the API & Internals score of the framework you’re considering as a backend is probably the most relevant part for you.
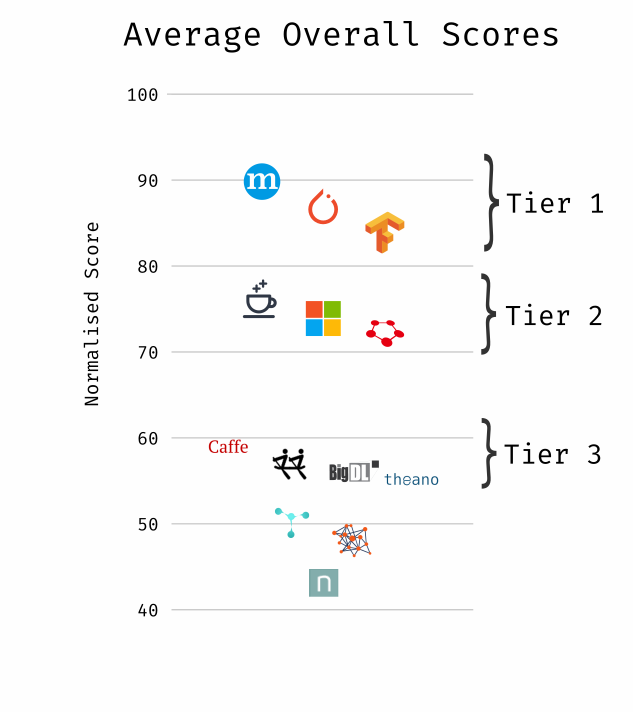
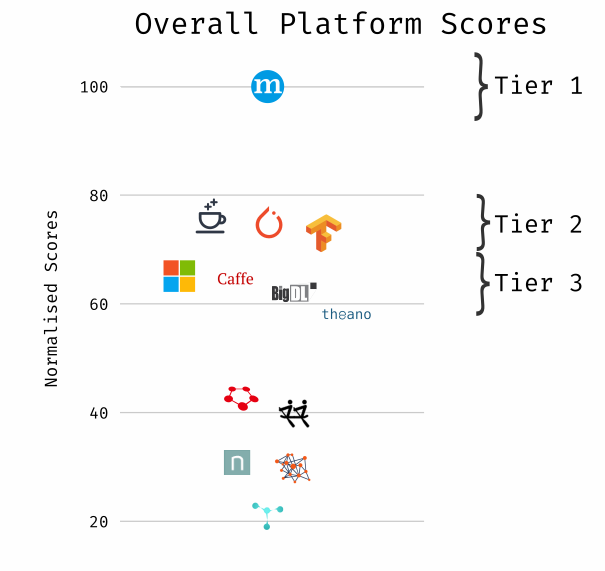
The Podium: Overall Results
We’ve all got deadlines, so I’ll cut straight to the overall scores of each framework (below). These overall scores are an average of the three category score. Again, for my fellow detail-geeks, I break down each category in later sections.
Apache MXNet takes the crown as the best all-around-er, followed closely by PyTorch and TensorFlow. Although it has the lowest Support & Community scores out of the top 3 frameworks, MXNet sneaks into the lead largely due to its dominant Platform score and its strong API & Internals score. MXNet was clearly benefitted in this overview by its focus on portability, with over 6 language bindings including Perl (really?), as well as its modern Gluon API, complete with dynamic graph building and great scale-conscious NDArray library.
Of course, perhaps developer mindshare is far more important to you than MXNet’s Perl support, or its multi-node-friendly NDArray library. In those cases, TensorFlow or PyTorch might be far better bets, with your desire for mature dynamic graph building or dependence on the Google Cloud Platform being the most likely tie-breakers.
Tier 2 is comprised of frameworks that scored very similarly in each category, with the exception of Chainer’s strong API & Internals score and weaker Support & Community score.
Frameworks that ranked outside of the first two tiers appear to be either abandoned, superceded, or fairly new and immature. Notable here is that PaddlePaddle is the only one framework in Tier 3 to have a particularly active development cycle (see Round One for more details).
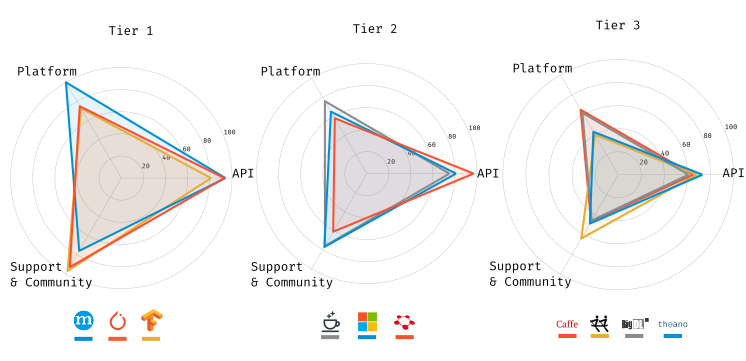
I promise the marketing team didn’t force me to make the radar plots look like the Coveo logo
The tiers here (and elsewhere in this document) aren’t standardized and don’t have a whole lot of meaning outside of the fact that it’s a convenient way of thinking about how frameworks are clustered in their scores.
You can continue on to the break-down of how frameworks fared in each category below, or skip ahead to the discussion that attempts to tie all these findings up in a nice narrative bow.
Round One: Support & Community
If you’re going to invest time and effort in a code-base that depends on a framework, you want to know that there’s a community of battle-testing, bug-reporting, ticket-answering, and fix-merging devs somewhere in the world.
Another great side-effect of having a large user base is that it’s more and more common to find implementations of popular papers and architectures that were originally written in another framework or (sadly more often) not supplied at all.
Category Criteria
| Criterion | Question it answers | Rationale | Scoring |
|---|---|---|---|
| Sponsor | How is the development of the framework funded? | The more money a framework has, the more likely it’s going to stay active long term. | 0 for an individual, 1 for sponsors who allocated few resources, and 2 for sponsors who allocated many resources. |
| Activity | What is the development activity of the framework? | Bugs are more likely to be patched and features to be merged with active dev’t. | Score is assigned as the sum of (1) the inverse of the last commit in weeks, and (2) the number of pull requests merged this month. |
| Ecosystem | Are people building models with this framework? | Having ready-made models of popular architectures and pre-trained weights can be a huge speed-up to development. | Sum of the number of the log GitHub repos and the log of StackOverflow questions1. |
| Documentation | Are the docs complete? | Ever tried writing code for a framework with bad documentation? Nigh impossible. Undocumented features might as well not exist. | Currently qualitative score from one to three2. |
Results
Below are the Support & Community scores, as well as a break down of each criterion by framework.
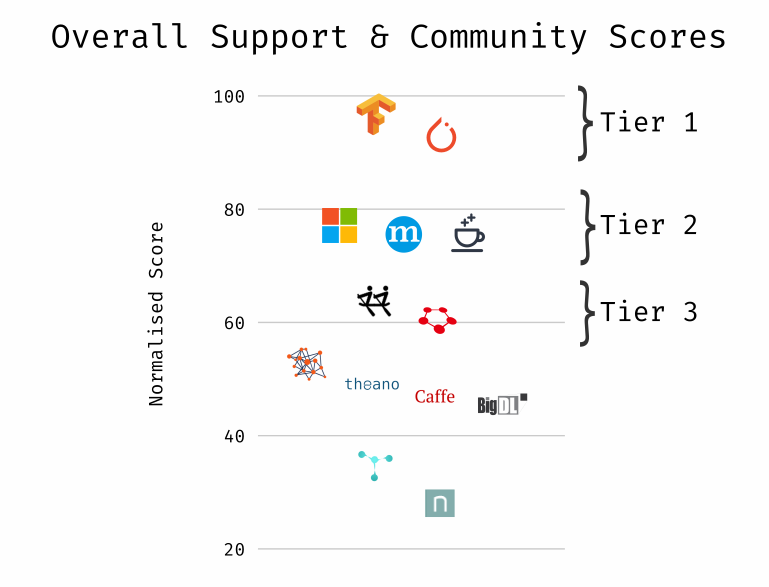
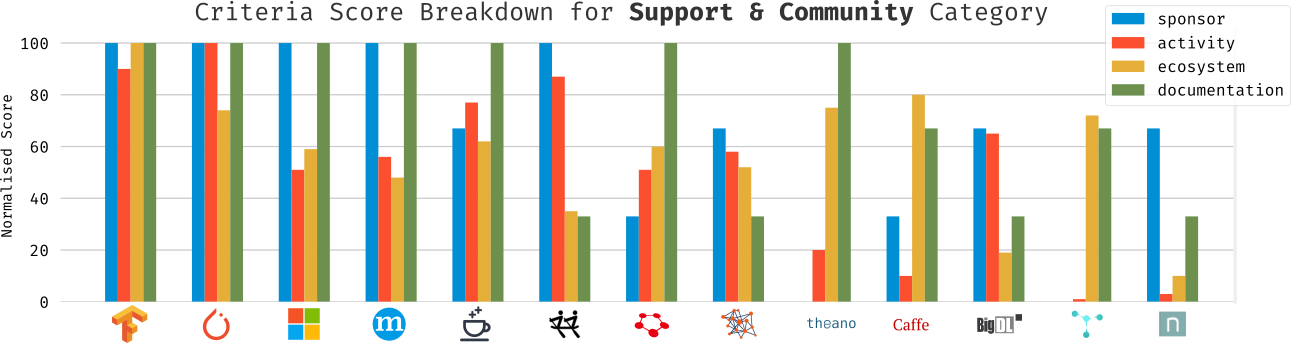
Breakdown of each criterion in this category by framework.
One of the more interesting scores in this category, in my opinion, is the ecosystem score. No framework’s ecosystem score can really hold a candle to TensorFlow. It should be said, however, that while it is far and away from the 3 year-old TensorFlow’s score3, PyTorch has in 1 year amassed an ecosystem that is not dissimilar to that of the far-older leaders of yesteryear like Theano, Caffé, or its older brother Torch. With growth like that, it’s not hard to see PyTorch as a challenger to TensorFlow’s current seat on the throne of developer mind-share.
CNTK and MXNet are two other frameworks with deep-pocket sponsors, but are hobbled in this category by middling ecosystem and development activity scores.
Finally, the pioneering trio of Theano, Caffé, and Torch have development rates that have reached maintenance levels for reasons one can speculate could range from approaching feature-completeness to being abandoned (as is certainly the case with Theano).
Round Two: API & Internals
This a under-the-hood, wheel-kicking section, where we look at what these frameworks can and can’t do, and what underlying tech they use to do it. Here’s how I measured that:
Category Criteria
| Criterion | Question it answers | Rationale | Scoring |
|---|---|---|---|
| Sym/Dyn Graph4 | Does the framework support dynamic, or old-school symbolic computational graph building? | There’s too much to say on the topic to fit here, but here’s a great talk. The main take-away for us is that symbolic graph builders need their own API and require a compile step while dynamic ones don’t. | 2 for dynamic, 1 for symbolic, and 0 for neither/manual. |
| Numerics | What numeric backend is being used? Is it actively developed? Easy to use? | Deep learning libraries are often deeply integrated with numerics libraries, and having mature, easy-to-use numerics libraries is very important to being able to write custom layers as well as downstream applications. | Score of 0-5 for maturity, score of 0-5 for ease-of-use, activity score equal to sum of the inverse of the number of weeks since last commit and number of merged pull requests in the last month. |
| OOTB NN Ops | What are the out-of-the box neural network layers and operations that are supported? | The pre-built Legos that make up all networks, you definitely want to be able to reach for a wide variety of layer types, ranging from run-of-the-mill convolutional layers, to LSTMs. | 1 point for every implemented layer/optimizer of a sample of 32 that I identified. 0.5 for cases where implementing the layer is particularly trivial. |
Results
Below are the API & Internals scores, as well as a break down of each criterion by framework.
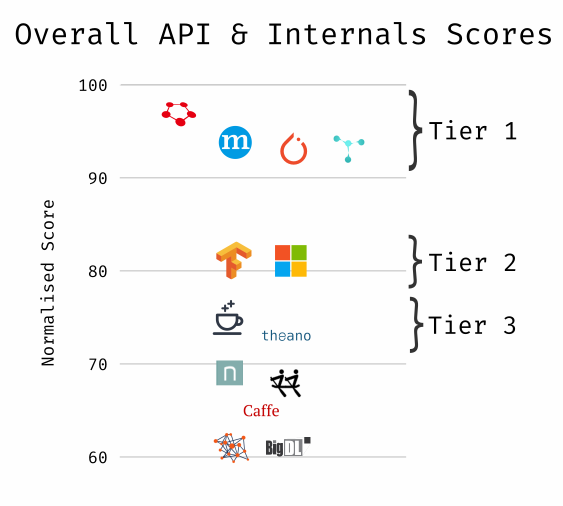
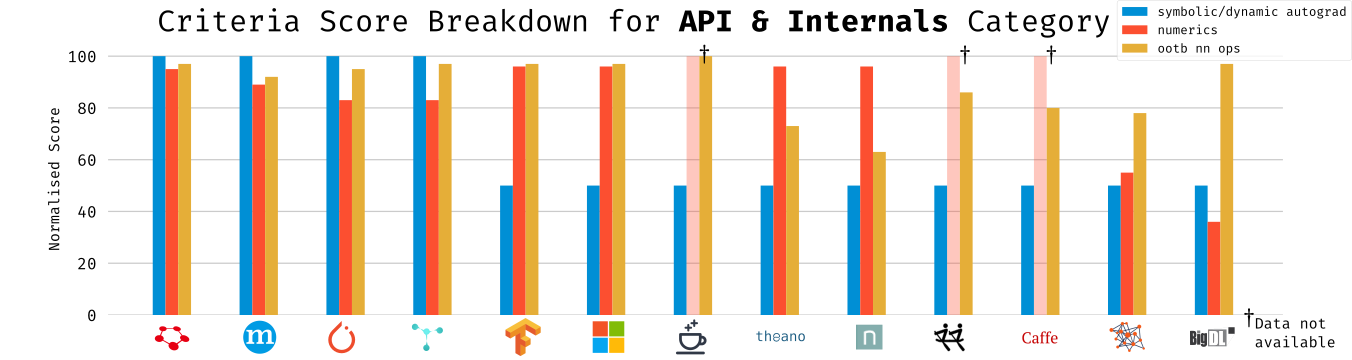
Breakdown of each criterion in this category by framework.
I wasn’t able to determine a numerics score for Caffé, Caffé2, and PaddlePaddle, so that criterion is not factored in their category average.
This category is largely skewed by the symbolic/dynamic graph building score, but that’s as intended. From personal experience and the anecdotal experience of smart people I respect, dynamic-graph building offers a flexibility and natural flow that Keras/Lasagne’s5 familiar and forgiving “stacked-layers” approach is often incapable of.
I can’t help but foresee the grumblings of TensorFlow loyalists who have by now realized I’ve marked TensorFlow as having a symbolic computational graph builder despite the new “Eager Execution” mode it rolled out fairly recently. While there are a number of reasons why I did not consider it, it mostly boils down to TF’s “eager” mode striking me as a bit of a second thought, as it suffers from performance issues and likely is not suitable for production use. Still, it’s very cool to see that TensorFlow has the introspective capacity (and developer hours) to address concerns over a more usable PyTorch developer experience.
In regard to out-of-the-box neural network operations, most modern networks have more or less coalesced on a set of flexible and reusable operations that make everyone’s life easier. Still, some more exotic but useful layers like Hierarchical Softmax are few and far between (which is probably fine, but I’d personally love not having to reimplement it every time I move between frameworks). I know I might be “dynamic graph fanboy”‘ing a bit, but having a dynamic graph also helps you to use operations in a more portable way, freeing you from having to always rely on built-in ops and the framework’s specific API.
Round Three: Platform
Being able to integrate a framework into your existing code base and stack is a big consideration when deploying deep-learning models in production. This category tries to measure your ability to do so with ease by taking into account things like the number of mature API bindings, OS support, and built-in solutions for scalability.
Category Criteria
| Criterion | Question it answers | Rationale | Scoring |
|---|---|---|---|
| API Languages | Are there many, mature, language bindings? | Having multiple language bindings offers flexibility for integrating into existing code bases, as well as ergonomics when APIs are written in expressive, dynamic languages like Python. | +1 for each language, weighted by maturity (0-1) of the binding. |
| Scalability | Does this framework support (easy-to-use) multi-machine training/prediction? | Deep Learning is a fellow hype-word and best friend to Big Data, which means easy cluster computing and data parallelism are very valuable. | 0 if none available, 1 for 3rd party solutions, and 2 for out-of-the-box support |
| OS Support | Are many OS environments supported? | Being able to develop and deploy on any OS makes developing in teams and in heterogeneous environments a lot easier. | +1 for each OS officially supported. |
| AWS Support | Is it easy to use in the Amazon cloud? | Being able to deploy to autoscaling clusters in the cloud is a beautiful thing. We’re focusing on AWS here because Coveo’s cloud services are powered by Amazon. | 3 for officially endorsed, 2 for officially supported, 1 for example of it working, 0 for no information. |
| ONNX Support | Can we serialize models to the ONNX format? | ONNX is an exciting open format whose goal is to make models and their weights portable between frameworks. | 2 for built-in support, 1 for community support, 0 for no support. |
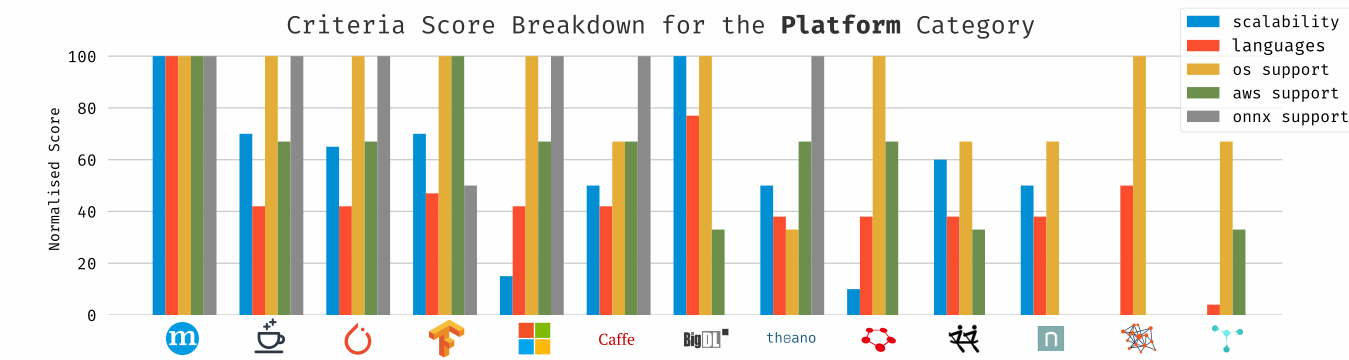
Breakdown of each criteria in this category by framework.
Well, there’s no other way to say it: MXNet blew past the competition here. It’s not much of a surprise, however, as being able to run on a wide variety of machines is pretty much MXNet’s raison d’être. Its tagline is “A Scalable Deep Learning Framework”, after all.
ONNX invites the very interesting proposition of writing your code in a framework you find flexible and easy to debug (e.g. PyTorch) and deploy it on a framework which has either the language bindings you need, or works well in a certain cloud environment (e.g. Apache MXNet or CNTK). The only more recent framework not to have some degree of built-in support of ONNX is really TensorFlow, and that’s largely due to some boring politicking. Worth mentioning: while I couldn’t find any references to ONNX support in DL4J, they do support import Keras models, which can be a useful way of designing architectures or training networks and deploying them on the JVM. All the same, it’s not quite ONNX, as Keras isn’t exactly a panacea (despite being very popular).
Discussion
Closing the Hardware-Software Gap
If you haven’t already heard the much-repeated and over-simplified6 parable of how Neural Network came to be the stuff of hype-legend, it begins with some ahead-of-their-time visionaries in the 60’s that over-promised, under-performed, and eventually led the field into becoming a research-funding pariah. Not to discount the theoretical advances that happened during that time, but one of the largest barriers that was lifted between the AI winter of the 1970s and the deep-learning mania of the 2010s is the hardware barrier7. Accessible and affordable compute units were being pumped out en masse in the form of consumer GPUs marketed towards the gaming and PC enthusiast community.
I think that if the explosion of the number of deep learning frameworks and the lack of clear winner tells us that we’re behind the eight-ball when it comes to mature software solutions to take advantage of the surprisingly bountiful compute harvest GPUs have given us. Part of that is that while the hype-train is travelling with great acceleration, it only left the station somewhere around 2012. We’ll close the gap eventually, and posts like these will disappear, but what that future will look like is, as always, uncertain…
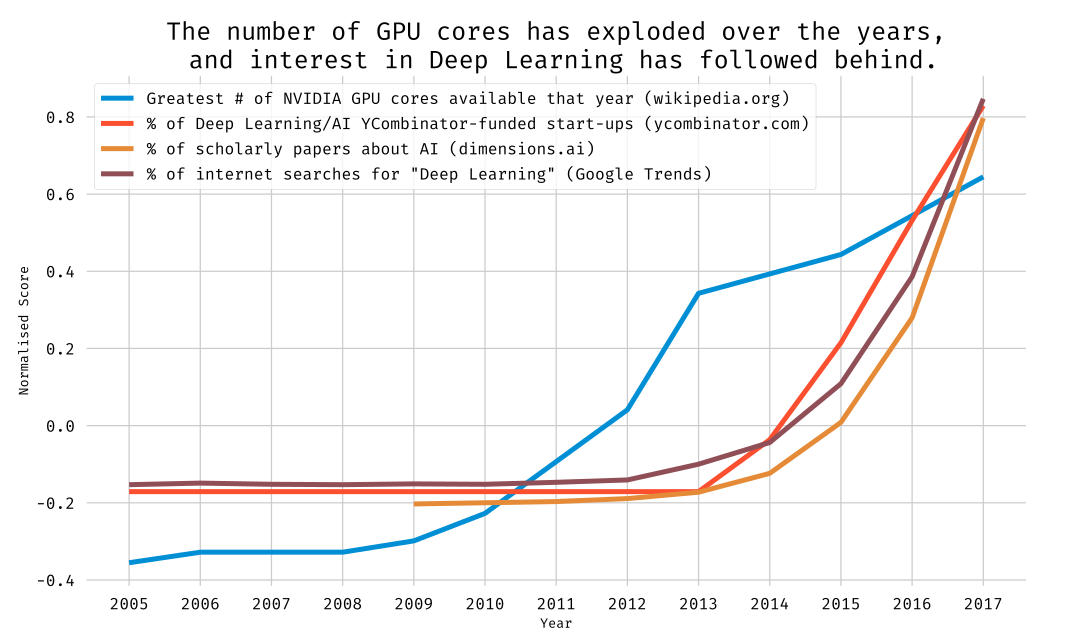
I’m not asserting correlation implies causation, but I am trying to illustrate that mindshare in AI has been outpaced by hardware advancements.
Monoculture, Triumvirate, or Plurality?
It’s clear that Google is banking on a TensorFlow hegemony, from their hesistance to join ONNX to how they’ve positioned TensorFlow in the Google Cloud Platform, not to mention the resources they’ve spent on software and hardware development.
However, with the efforts of Facebook’s devs and Amazon’s platform support, we might just as likely see a triumvirate of tech giants; each sharing equal bits of market share and staking out segments like academics or people running on the Google Cloud. While that might seem to be the case at the moment, much like the Roman Triumvirates, I don’t foresee them being particularly stable or lasting long. Developers long for interoperability and the ability to bring tech to whatever stack is in fashion.
Which bring us to what I think is the most likely outcome: a wide plurality of interoperable frameworks. I think there are a couple of factors that support this. The first being that, as mentioned earlier, devs want to be able to move software between stacks. Secondly, an often underestimated consideration, in my opinion, is that there are far more people who can make use of existing neural network architectures, than those who know or need to design new ones. What’s more is that ratio is probably only going to increase over time as more public models get written.
The Take-Away?
My advice? You don’t need to chose a framework that’s both great at prototyping/designing an architecture as well as deploying and serving those models.
First, find a framework that you enjoy programming in that exports to ONNX (my personal favourite is PyTorch). Then, when/if you need to move to a non-Python code-base or need to deploy to a cluster or mobile environment that your prototyping framework doesn’t play nicely with, switch to a framework that supports your environment best and can import ONNX (which is likely going to be Apache MXNet).
Projects like TVM8 have already embraced this hybrid approach, leaving the programmer productivity to existing frameworks, and focusing on support for a large number of diverse deploy languages and platforms.
I hope that was helpful! Leave any questions, concerns, or overwhelmingly positive feedback down in the comment box below!
Footnotes
0. There are a number of experimental backends like MXNet and DL4J also in the pipeline. Writing backends for Keras is actually not a horrible experience, which is pretty cool. ⮌
1. It’s important to bear in mind that this measure is on a log scale later on. It means that TensorFlow is super dominant and that Neon might as well not exist. ⮌
2. If you can think of a less subjective measure for this or any other metric, leave a comment! Would love to read them. ⮌
3. Again, just a reminder that the ecosystem score is logarithmic, so even small differences here are important. ⮌
4. The definitions I use for “symbolic” and “dynamic” graph builders are from this presentation (slide 43 and onward). Some people term what I refer to as “symbolic computational graph building” as “static computational graph building.⮌
5. Lasagne, for those summer children out there, is/was(?) a predescessor to Keras that had a very similar API, but built for Theano exclusively. It was pretty awesome at the time.⮌
6. For an in-depth version that doesn’t resort to simplifications bordering on apocrypha for narrative’s sake, you can check out this great article. ⮌
7. Let me be clear, the hardware barrier wasn’t the only hurdle to clear on the road to practical and efficient deep learning. We weren’t always able to store and process data at the scales that we currently are, and seeing as data is the fuel which machine learning runs on, the “data barrier” was a considerable one. Furthermore, essential advances made in optimization also contributed to bringing us to where we are today. ⮌
8. TVM wasn’t included in this comparison because it’s less of a framework for the designing of networks, and more of a way to compile models into environments the original frameworks don’t support. It’s a super interesting project that I think deserves more attention. ⮌