When configuring your servers, there are some aspects to consider. Depending on your needs, you will need to implement the most beneficial scalability model. We will be highlighting some options that can guide you along. The first aspect to consider is the amount of documents. You see, as the number of documents in your index increases, hosting the index on a single hard disk can often lead to size and performance limitations. In this scenario, consider adding a slice. The slice is in effect, a separate physical storage location for a section of the master index and distributes the index content, hence increasing available space. It’s possible that it can potentially speed indexing once you have passed a certain threshold, so add a slice when it’s needed. A slice can potentially contain up to 40million documents, and since one Coveo server can typically host up to two slices, it would then contain up to 80 million documents evenly distributed between the two. Potential problem averted!
Memory and CPU levels, are other factors to keep in mind. To put it simply, the greater number of CPU cores, the better. In what exact situation should I add CPU cores, you might ask? Well, when you find your users entering queries with numerous terms, exact match operators or wildcard characters, high number of documents to convert and if you use the OCR module these operations are CPU dependent. So to give an example of a server with an index size between 5 to 20 million documents:
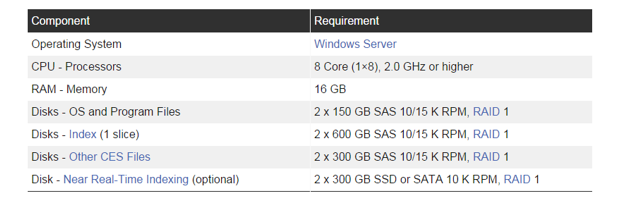
Of course, the number of needed cores increase with the size of the index. Primarily, we are including physical memory in the equation, since indexing uses a lot of physical memory to pre-compute mappings. Querying your index also requires a great deal of physical memory for caching. Other examples are facet, string or numerical fields that have to be basically pre-loaded in memory. Simply put, the more memory CES has at its disposal, the faster the data in your index can be queried, your end users cannot query data in an unwritten transaction. The transaction is a unit of data that CES keeps in its memory until it’s written in the index, so if CES has 32GB of RAM available, it can commit larger transactions than if it had only 16GB. Often times, the need to ensure that queries and query loads can always be maintained and served will necessitate the addition of Mirrors as part of your infrastructure. This will essentially share the query bearing load and in the event that your main server is unavailable for any reason, you can immediately point the query serving server to the mirror, problem solved! Simply put, if the number of end user queries will potentially slow down your master server, add a mirror! Here’s a quick pic to illustrate how a mirror can help in a network that is well load-balanced:
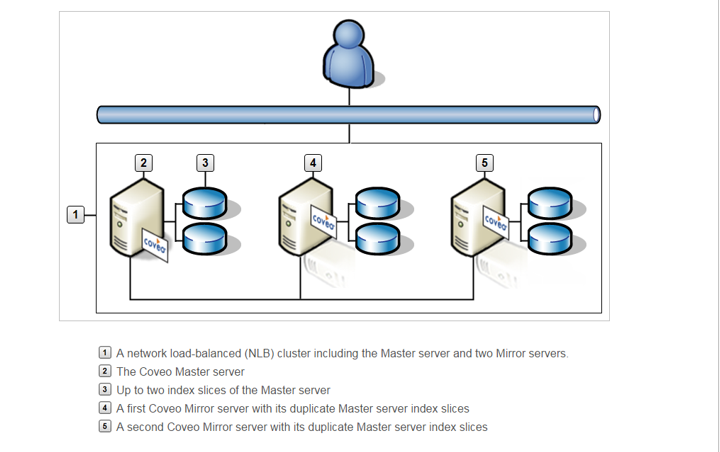
So you we can see, the master server is supported by two mirror servers already having slices configured. And for a fuller picture, check this out:
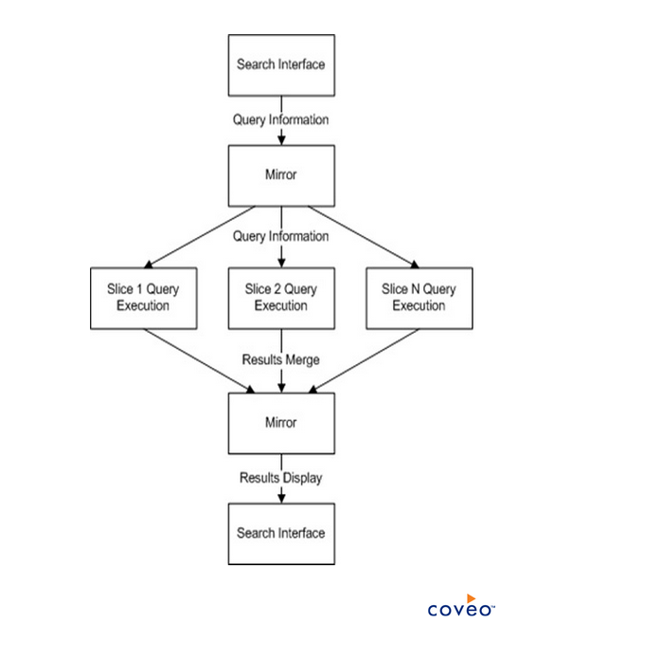
Now, CES is of course designed to function properly as long as its host server meets the minimum hardware requirements. So disk selection is important. The index should be installed on a dedicated hard disk. As an example, if your index documents occupy 1TB in various repositories, with such a mix of content type, the index size could end up at 42% of the original documents size (420 GB). The size of the dedicated index hard disk should at the very least be 500GB. We also recommend at least 1GB of available space to install the CES software on the system hard disk. Low latency on your disk is also important both for indexing and querying speed.
Another aspect that we’d like you to ponder, is the freshness of your index. This is also important to consider, giving that the index pipeline processing time may greatly vary depending on numerous factors such as the index size, the number of new documents to index at a given time, and the available resources on your Coveo Master and Mirror servers. Also, indexing can only go as fast as the crawled repository can feed us the documents. Hence, it’s possible that the bottleneck might not be CES-related. Near Real-Time indexing is a newer feature that improves the freshness of your index, thereby making new documents searchable faster. NRTI creates small temporary slices called subslices to receive new, changed, or deleted indexed documents. Because subslices are much smaller in size than a regular slice of a large index, their index pipeline processing is completed much faster, allowing to return queried documents they contain much faster. The feature kicks in by default when reaching a million documents. Look at the below table for recorded improvements:
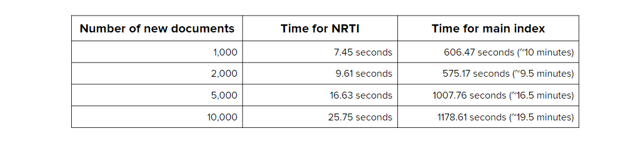
The table speaks for itself. Use NRTI at your leisure! A side note on this: When the Coveo server does not meet the requirements and large sources are rebuilt on top of a normal flow of new documents, the index pipeline processing time may prolong by a few days and enabling the NRTI feature will most likely not help because the server is lacking resources. So normal recommended practices should be applied in other for this feature to be truly effective. This feature has been enabled by default since the CES build 7.0.7022. Since NRTI is an I/O intensive process, to achieve optimal performance, we recommend the addition of one dedicated disk for the NRTI files on each Coveo server that are serving queries and point to that disk, and as always, the dedicated disk specifications depend on the size of your index as we had previously illustrated. With all these in mind, the Coveo support team is currently building a tool that will greatly aid you in determining on a case by case basis, what would be the best infrastructure to implement for CES to flourish. It promises to greatly help simply this potentially difficult task and avoid issues down the line. An upcoming blog will provide details. Stay tuned!